How We Built a Content Recommendation System With Pgai and Pgvectorscale

We at Pondhouse Data build customized AI applications as part of our professional services, from self-hosted chat applications to tailored AI model training, like content recommendation systems. All our projects have the following requirements:
- The projects need to reduce complexity as much as possible, as we are a small team.
- We need easy access to large language models (LLMs) without needing to set up extensive infrastructure.
- Most of the time, we need some sort of vector search, as retrieval-augmented generation (RAG) is currently one of the most useful and economic AI applications.
- Our applications need to be multi-tenant as our clients mostly want to resell their AI tools to their customers—in an industry that is enormously concerned with data privacy.
That's where we fell in love with pgai and pgvectorscale, as both tools perfectly fit our requirements and were essentially a milestone for building AI projects in PostgreSQL.
In this blog post, we'll show you one of our more recent projects, provided as a hands-on guide. We'll walk you through our process of building a content recommendation system for SEO-related internal link building using pgai and pgvectorscale. A content recommendation system is an algorithmic tool used to suggest relevant content (such as articles, products, or media) to users based on their preferences, behavior, or characteristics.
At the end of this post, you'll have a sound understanding of how to use both pgai and pgvectorscale, and also why both tools are currently one of the best solutions for the problems they are solving.
What is pgai, and why you can build a content recommendation system with it
Pgai is a PostgreSQL extension that provides PostgreSQL functions to interact with AI models. In simpler terms, pgai allows you to directly invoke LLM APIs using PostgreSQL queries right from your database.
Use cases for pgai
Among the many use cases for pgai, the following are most common in our experience:
- Tagging and categorizing data: Modern LLMs are particularly good at creating tags and categories for textual content. Historically, one would need to set up a separate tagging service, continuously fetching and processing the inserted data, sending them to an LLM, processing the answer, and updating the respective rows in the database.
With pgai, this process can be simplified to a single database query.
- Moderating content: As LLMs are able to understand the content of a text reasonably well, they can be used to automatically moderate content, e.g., by detecting hate speech or other harmful content.
As for the use case above, using pgai, this can be done with a single query.
- Summarizing content: Similar story as for tagging and categorizing data—summarizing content can be done with a simple query.
- Creating vector embeddings for texts: Vector embeddings are one of the most useful tools in AI applications. They single-handedly power most AI-based search applications based on retrieval-augmented generation.
Again, the process of creating embeddings required quite a good amount of infrastructure to be set up—and similarly to the use cases above, they can now be done with a single query.
If you have a hard time imagining how this works, we'll show you in a second. The application we are demonstrating here requires three of the four use cases above, so you'll be served with a good number of examples in a second.
What is pgvectorscale?
If you work with PostgreSQL and AI, you most certainly already heard of pgvector. It's a PostgreSQL extension for storing and searching vectors. It's a tremendous piece of work and deservedly one of the most admired tools in all of the PostgreSQL AI ecosystem. It simply adds a vector type to PostgreSQL, accompanied by various search operators and indexes. This allows storing vectors side by side with ordinary PostgreSQL data (think, metadata) and using the full suite of PostgreSQL capabilities on both the metadata and the vectors.
While pgvector in itself is a great tool, it has two shortcomings when it comes to scalability. Its most prominent index for larger amounts of data is the HNSW index. It's reasonably fast but has two problems:
- You need to have the whole index in memory, or it gets slow. This makes the index the exclusive bottleneck for the whole application.
- HNSW index-based searches can't take advantage of pre-filtering in a meaningful way. Searching for vectors with HNSW always first runs the index search, fetches the results, and only then applies the filter. To add insult to injury, HNSW can only return a maximum amount of results from the search (less than 1,000 in most cases, otherwise it gets quite slow). Now imagine that you have a multi-tenant application with several thousand teams, and each has thousands of texts (and vectors). HNSW will search all vectors for your search query, return a limited amount of results, and only then apply your filter on team. There is no way to guarantee that you'll even find any vector for your team—if, for example, the best fits for your search query would be in a team not related to your search query.
team_id). However, if you have thousands of items, this becomes impractical. Additionally, you lose the flexibility of filtering on all available metadata.That's where pgvectorscale comes into play. It's an extension for pgvector, adding a disk-based streaming index, addressing both of the above issues.
More specifically, it adds an index inspired by Microsoft’s DiskANN paper called StreamingDiskANN, which is a graph-structured index specifically made for always-up-to-date, filtered approximate nearest neighbor search. You can learn more about how pgvectorscale’s StreamingDiskANN vector index works under the hood in this technical explainer post.
This index solves both of our issues above: You don't need to have the full index in memory, and you can apply filters as you want.
streaming from StreamingDiskANN comes from. The index will process its graph-based structure for new data for as long as your limit statement is not satisfied. If you have a filtered query with LIMIT 20, the index will be traversed until 20 results are found (or until no data is available for processing anymore). Due to the sound structure of the index, this operation is very fast.On top of that, pgvectorscale is really fast. According to Timescale, pgvectorscale outperforms specialized vector stores by 28x.
Introduction to Our SEO Content Recommendation System
So, now that we know what pgai and pgvectorscale are, let's build ourselves a content recommendation system for SEO purposes.
Let's assume we are either content publishers (think news) or personal bloggers. We want to get more traffic to our site and also want our users to stay on our page for as long as possible. As we assume that our content itself is best-in-class anyway, there is a proven method to increase both SEO traffic and pages visited per session: adding internal links to our content. Makes sense, right?
If you are reading an article on a website and there is a link to a related article, you might stay a little longer. However, this internal linking is quite time-consuming. You need to find the right, related content and add the links organically throughout your article so as not to annoy your readers (and the Google gods) with link spamming.
That's where our AI-powered content recommendation system comes into play:
- Find related content to the article we are currently writing
- Automatically suggest inline links to the related content
- Optional: automatically add tags to our articles, as tags or categories can be used to further filter the related content
Vector embeddings (and RAG in general) are perfect for this task. To implement these requirements, we therefore need the following steps:
- Create a summary of all our available content
- Creating embeddings from these summaries
- Create a summary of the article we are currently writing
- Create embeddings from these summaries
- Search for similar embeddings
- Create suggestions for inline links to similar content
Note: Why do we need summaries before creating embeddings? Vector embeddings catch an approximation of the semantic meaning of a text. If the text is too long, this semantic meaning can't be meaningfully embedded. Our tests showed that vector-based similarity search works best on a per-sentence basis. While we can't reduce our whole text into just a sentence, a summary the size of a paragraph or two works reasonably well.
See the chart below for a visual representation of the process and which steps require pgai or pgvectorscale.
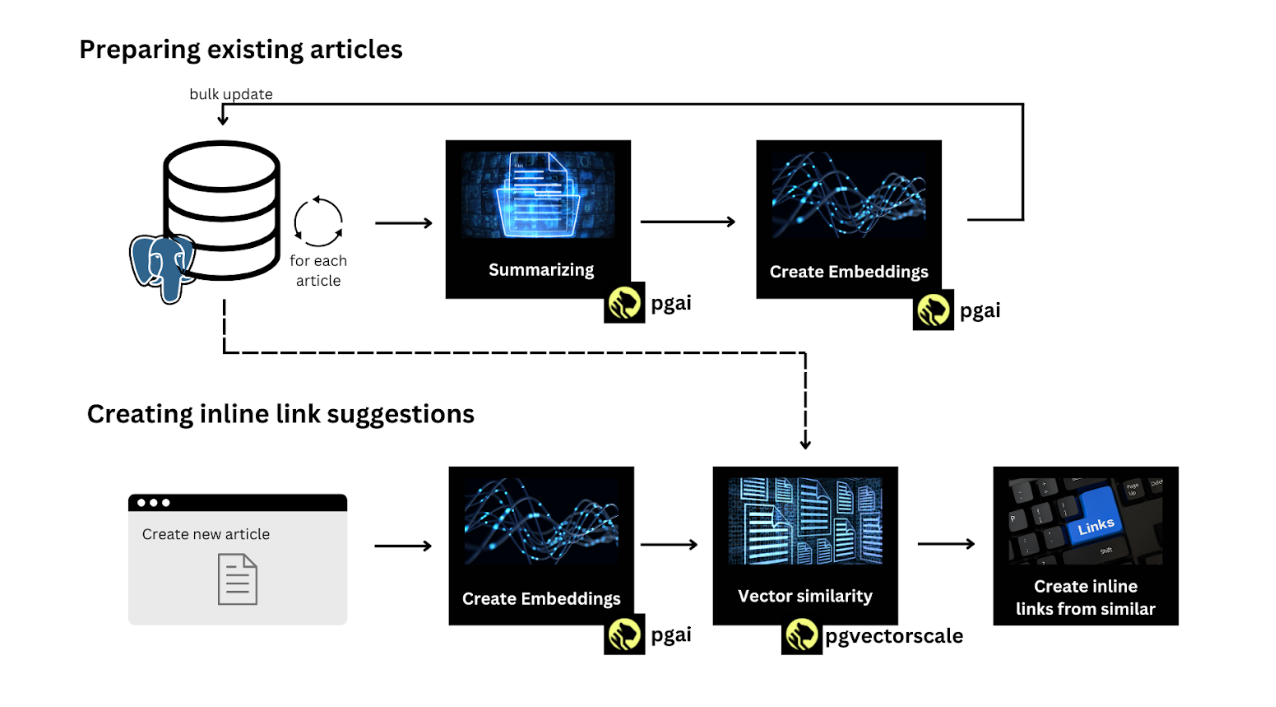
What you might notice from the chart above: We do not require any additional infrastructure. We only need PostgreSQL with pgai and pgvectorscale. This was the major eureka moment for our company: having modern LLM models available right from our database. No dependency management, no infrastructure, no additional costs.
Preparation: Installing Pgai and Pgvectorscale
Enough talk—let's get our hands dirty. (You will find all the code for this guide in our companion GitHub repository.)
To install pgai and pgvectorscale, there are multiple ways:
- Using the prebuilt TimescaleDB docker images
- Installing from source
- Using Timescale Cloud
For this guide, we'll simply use the pre-built TimescaleDB image, as it offers pgai and pgvectorscale out of the box.
If you want to use a different installation method, we'll link to them below:
To use the prebuilt image:
- Pull and run the image (change
<your-password>to your desired password):
docker pull timescale/timescaledb-ha:pg16
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=<your-password> timescale/timescaledb-ha:pg162. Prepare your API key for pgai. As we need to interact with LLMs, you want to provide an API key. In this tutorial, we'll use the OpenAI models.
- Add the API key to your terminal session:
export OPENAI_API_KEY="<your-api-key>"
- Add the API key as
PGOPTIONSto your database connection (see below).
3. Connect to the database:
PGOPTIONS="-c ai.openai_api_key=$OPENAI_API_KEY" psql -h localhost -U postgres # if running on your localhost
PGOPTIONS="-c ai.openai_api_key=$OPENAI_API_KEY" psql -d "postgres://postgres:<password>@<host>:5432" # if running remotely
# Optional: Connect to your database: \c my_database4. Create the extensions:
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;Preparation: Creating tables for the pgvectorscale vector search
- Run the following statements to create the tables for this guide. Note that these are simplified for the purpose of this tutorial. You are in no way bound to the columns, types, or names provided here.
CREATE TABLE IF NOT EXISTS blog_articles (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
content TEXT NOT NULL,
summary TEXT,
tags TEXT[],
embedding VECTOR(1536)
);
2. Create some dummy articles we might already have in our database:
-- First Demo Blog Article
INSERT INTO blog_articles (title, content)
VALUES (
'The Future of Artificial Intelligence',
'Artificial Intelligence (AI) is rapidly transforming various aspects of our lives, from the way we interact with technology to the way industries operate. AI systems are becoming more sophisticated, with advancements in machine learning, natural language processing, and robotics. This article explores the potential future developments in AI, such as enhanced machine learning algorithms, the rise of autonomous systems, and the integration of AI into everyday applications. We also discuss the ethical considerations and societal impacts of these advancements, including job displacement, privacy concerns, and the need for responsible AI development.'
);
-- Second Demo Blog Article
INSERT INTO blog_articles (title, content)
VALUES (
'Understanding Climate Change',
'Climate change is one of the most critical challenges facing humanity today. It refers to long-term changes in temperature, precipitation patterns, and other aspects of the Earths climate system. This article provides a comprehensive overview of climate change, including its scientific basis, observed impacts, and projections for the future. We delve into the greenhouse effect, the role of human activities in exacerbating climate change, and the potential consequences for ecosystems and human societies. Additionally, we explore strategies for mitigating climate change, such as reducing greenhouse gas emissions, transitioning to renewable energy sources, and implementing sustainable practices.'
);
-- Third Demo Blog Article
INSERT INTO blog_articles (title, content)
VALUES (
'Healthy Eating: Tips and Tricks',
'Maintaining a healthy diet is crucial for overall well-being and longevity. This article offers a variety of practical tips and strategies for improving your eating habits. We cover topics such as the importance of balanced nutrition, understanding macronutrients and micronutrients, and the benefits of incorporating a diverse range of foods into your diet. The article also provides advice on meal planning, mindful eating, and making healthier choices when dining out. By following these tips, you can enhance your nutritional intake, support your physical health, and improve your quality of life.'
);
This should do the trick for now. We have three blog articles, with content and title.
Creating Summaries and Embeddings for Existing Texts
Now, let's create some summaries and embeddings. Pgai invokes LLMs by making simple REST API calls to their respective API providers. In our case, we want to use the OpenAI chat completion API.
Looking at the OpenAI API specification, or more specifically, the Python examples for how to invoke bespoke API, we see that we need to create an object with model and messages, where the latter contains the messages we want to exchange with the model.
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
```
The response will be similar to:
```json
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The 2020 World Series was played in Texas at Globe Life Field in Arlington.",
"role": "assistant"
},
"logprobs": null
}
],
"created": 1677664795,
"id": "chatcmpl-7QyqpwdfhqwajicIEznoc6Q47XAyW",
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"usage": {
"completion_tokens": 17,
"prompt_tokens": 57,
"total_tokens": 74
}
}
The answer we are looking for is in the content field of the message object.
We can now adjust the Python syntax to a PostgreSQL query as follows:
SELECt openai_chat_complete
( 'gpt-4o'
, jsonb_build_array
( jsonb_build_object('role', 'system', 'content', 'Your task is to summarize blog posts. The tone should be neutral and informative.')
, jsonb_build_object('role', 'user', 'content', 'Text to summarize: ' || content)
)
)->'choices'->0->'message'->>'content'
FROM blog_articles
LIMIT 1
;
Let's break down what we are doing here:
- We use the
openai_chat_completefunction from pgai to invoke the OpenAI chat completion API. - The first argument is the model we want to use;
gpt-4oin this example. - The second argument is the messages array. We use the built-in json functions to create a JSON array with one system message and one user message. Note that we concatenate the
contentfield from theblog_articlestable to the user message. - Last but not least, we use the PostgreSQL JSON field operator
->to extract the content from the response. More specifically, we selectchoices[0].message.content.
If we run this very query above, we'll get the summary of one of our blog posts.
If we want to update all our blog posts with their own summary, we simply need to transform the SELECT query into an UPDATE one:
UPDATE blog_articles
SET summary = openai_chat_complete
( 'gpt-4o'
, jsonb_build_array
( jsonb_build_object('role', 'system', 'content', 'Your task is to summarize blog posts. The tone should be neutral and informative.')
, jsonb_build_object('role', 'user', 'content', 'Text to summarize: ' || content)
)
)->'choices'->0->'message'->>'content'As simple as that, we created for ourselves a method to bulk-create summaries for all our blog articles. Looking at this example, this is where the strength of pgai is rooted in: You can use the full power of the PostgreSQL query language together with AI models. SELECT, UPDATE, INSERT—even TRIGGERS can be used to invoke these models.
Creating the embeddings from our summaries is very similar. We'll use the openai_embed function for that.
UPDATE blog_articles
SET embedding = openai_embed('text-embedding-ada-002', summary);The first parameter again described the model to use; the second parameter described the text to send to the model.
Automatically creating summaries and embeddings on save
As a step further, we not only can update our whole database in bulk with embeddings and summaries, but we might also implement a feature that automatically creates embeddings and summaries when an article is saved (think, inserted in our database).
For that, we can use PostgreSQL insert triggers.
PostgreSQL triggers come in multiple flavors. You can run them before or after an INSERT, UPDATE, DELETE or TRUNCATE statement. In our case, we want to run it before an INSERT statement, as we want to add the embeddings and summaries to the newly inserted row.
A trigger in PostgreSQL requires two things:
- A function, that is executed when the trigger happens
- The trigger definition itself
CREATE OR REPLACE FUNCTION create_embedding()
RETURNS TRIGGER AS $$
BEGIN
NEW.embedding = openai_embed('text-embedding-ada-002', NEW.content);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;and
CREATE TRIGGER create_embedding_trigger
BEFORE INSERT OR UPDATE ON blog_articles
FOR EACH ROW
EXECUTE FUNCTION create_embedding();Let’s test whether this works:
INSERT INTO blog_articles (title, content)
VALUES
(
'Exploring the Wonders of Quantum Computing',
'Quantum computing represents a groundbreaking shift in the field of computing, promising to solve problems that are currently intractable for classical computers. This article delves into the fundamental principles of quantum computing, such as superposition and entanglement, and how they enable quantum computers to perform complex calculations at unprecedented speeds. We explore the potential applications of quantum computing in areas such as cryptography, material science, and optimization problems. Additionally, we discuss the current state of quantum technology, the challenges facing its development, and the future prospects for its integration into real-world applications.'
),
(
'The Rise of Remote Work: Opportunities and Challenges',
'Remote work has become increasingly prevalent in recent years, driven by advancements in technology and shifting attitudes toward work-life balance. This article examines the rise of remote work, including its benefits such as increased flexibility, reduced commuting time, and access to a global talent pool. We also address the challenges associated with remote work, including maintaining productivity, fostering team collaboration, and managing work-life boundaries. The article offers strategies for individuals and organizations to effectively navigate the remote work landscape, including tips for creating a productive home office, leveraging digital tools for communication, and implementing best practices for remote team management.'
);
If we select these articles, we should see that the embeddings are automatically created.
SELECT * FROM blog_articles
WHERE title IN ('Exploring the Wonders of Quantum Computing', 'The Rise of Remote Work: Opportunities and Challenges');We can create a similar trigger for the summaries—which is left out here, as it's a simple copy-paste.
Searching for Similar Content With Pgvectorscale
We've come quite far already. We prepared all our articles and can create summaries and embeddings for our newly inserted articles. All that's left is to implement a feature which finds articles which are similar to one where we want to add inline links.
That's where we finally can use pgvectorscale.
First, to make use of the StreamingDiskANN index, we need to create this index type on our VECTOR column:
CREATE INDEX blog_articles_embedding_idx ON blog_articles
USING diskann (embedding);And secondly—already last—we can search for similar articles by using cosine distance as a similarity measure. In short, the cosine distance allows for determining how close together two vectors are. In LLM embeddings, the closer two embeddings are, the more similar the corresponding texts are.
The query we want to run is this:
SELECT title, content
FROM blog_articles
ORDER BY embedding <=> <embedding of the article we are currently writing>
LIMIT 10;The <=> operator is a special operator provided by pgvector (and used by pgvectorscale) for cosine distance. In pseudo-terms, this query should give us 10 articles that were most similar to the article to which we want to add inline links. How to generate the embeddings of the article in question? Easy, we simply use the openai_embed function from pgai again.
SELECT title, content
FROM blog_articles
ORDER BY embedding <=> openai_embed('text-embedding-ada-002', 'Article text...')
LIMIT 10;For convenience, we can wrap this query into a function that takes the article text as a parameter. We also add the number of similar articles we want to return (the LIMIT clause) as a parameter and return the distance to see how similar articles are.
CREATE OR REPLACE FUNCTION find_similar_articles(article_text TEXT, result_limit INT)
RETURNS TABLE(title TEXT, content TEXT, distance FLOAT) AS $$
BEGIN
RETURN QUERY
SELECT
blog_articles.title,
blog_articles.content,
(blog_articles.embedding <=> openai_embed('text-embedding-ada-002', article_text)) AS distance
FROM blog_articles
ORDER BY distance
LIMIT result_limit;
END;
$$ LANGUAGE plpgsql;To call the function, we simply execute:
SELECT * FROM find_similar_articles('Artificial Intelligence directly from your database', 10);The result should look something like the following. If you used the same text examples as provided in this article, you should find the article about 'The Future of Artificial Intelligence' as the most similar one—and therefore on top of the list. Furthermore, the distance should be the lowest for this article. Output example:
The Future of Artificial Intelligence |
Artificial Intelligence (AI) is rapidly transforming various aspects of
our lives, from the way we interact with technology to the way industries
operate. AI systems are becoming more sophisticated, with advancements in
machine learning, natural language processing, and robotics. This article
explores the potential future developments in AI, such as enhanced
machine learning algorithms, the rise of autonomous systems, and the
integration of AI into everyday applications. We also discuss the ethical
considerations and societal impacts of these advancements, including job
displacement, privacy concerns, and the need for responsible AI
development.
| 0.14593935882683595
Filtering with pgvectorscale
As already mentioned in the introduction, pgvectorscale is one of the few vector store solutions out there with full metadata filtering without compromises.
If we extend our example application a bit to include a multi-team setup, each team should only get recommendations for articles from their own team.
ALTER TABLE blog_articles ADD COLUMN team_id TEXT;
If we want to only include the articles from team team_1 in our vector search, all we have to do is add a WHERE clause:
SELECT title, content
FROM blog_articles
ORDER BY embedding <=> <embedding of the article we are currently writing>
WHERE team_id = 'team_1'
LIMIT 10This is—from our point of view—the major contribution of pgvectorscale. While you can also use WHERE clauses with plain pgvector, these clauses are only applied after the HNSW index search is done. This leaves you with potentially no results found for your team, as all of the most similar texts are found in another team’s repository.
HNSW can only maintain a limited amount of nearest neighbors to search for. You can set this by defining the ef_search parameter, as described here.
You can circumvent this issue by using either composite indexes or table partitioning; however, both solutions are not practical if you have hundreds or thousands of teams.
With StreamingDiskANN, however, there is no such limit. The index will be traversed for as long as there are neighbors to find.
Compared with other, more specialized vector stores, having the full capabilities of a relational database on both metadata and vectors at your disposal is a huge advantage. You could even use joins to bring in additional meta-information from your other tables.
Conclusion
In this blog post, we've demonstrated how to build a content recommendation system for SEO-related internal link building using pgai and pgvectorscale. We've walked through the process of creating summaries and embeddings for existing texts, automatically generating them for new content, and implementing a search function for similar articles.
After using pgai and pgvectorscale for many weeks now, their power clearly lies in their seamless integration with PostgreSQL, allowing us to use the full capabilities of the database while incorporating AI functionalities.
In the end, it's mind-blowing that using these two tools, we can build a fully functional RAG recommendation system with three simple database queries:
- Creating summaries
- Creating embeddings
- And searching for similar content
Key takeaways from this guide include:
- Using pgai to generate summaries and embeddings directly within the database
- Implementing triggers to automatically create embeddings for new content
- Utilizing pgvectorscale's StreamingDiskANN index for efficient vector similarity search
- Creating a custom function to find similar articles based on content
- Filtering search results based on metadata
Accessing and learning more about pgai and pgvectorscale
Both pgai and pgvectorscale are open source under the PostgreSQL License and available for use in your AI projects today. Installation instructions are on the pgai and the pgvectorscale GitHub repositories. You can also access these extensions on any database service on Timescale’s Cloud PostgreSQL platform.
For additional reading on pgai and pgvectorscale, you can explore these related resources: